Rapport d’enquête sur l’utilisation des graphes nommés du patrimoine culturel (partie 1)
Version : 1.0
Co-auteurs : George Bruseker (Takin.solutions)
Date : 2022-03-11
Introduction
Ce rapport est basé sur une enquête organisée en collaboration avec le Réseau canadien d’information sur le patrimoine (RCIP) et Takin.solutions et destinée à la communauté du CIDOC CRM. L’enquête visait à comprendre l’utilisation réelle des graphes nommés dans la mise en application pratique et la gestion des jeux de données sémantiques qui ont adopté l’ontologie CIDOC CRM. Afin de guider la prise de décision sur l’utilisation des graphes nommés par le RCIP, il a été jugé préférable de consulter les principaux spécialistes du domaine de la sémantique et du CIDOC CRM pour comprendre les meilleures pratiques actuelles. Le RCIP pourrait utiliser ces informations non seulement pour comprendre l’utilisation actuelle, mais aussi pour établir une projection de l’utilisation future probable et des possibilités d’harmonisation et de standardisation entre les projets. En ce sens, grâce à cette enquête, le RCIP pourrait chercher à comprendre, en ce qui concerne son travail en cours sur le sujet, comment il pourrait jouer un rôle dans la communauté des données sémantiques patrimoniales canadiennes en général en aidant à faire avancer la conversation pour des directives et une compréhension communes concernant l’utilisation de cette technique dans la pratique.
L’enquête visait à obtenir des réponses de la communauté du CIDOC CRM en publiant un questionnaire (généré dans Google Forms) auprès de la liste de diffusion du CIDOC CRM SIG (crm-sig@ics.forth.gr), afin d’obtenir des réponses de la communauté. La question originale (voir « Named Graph Usage Recommendations/Guideline Document », Question no. 526 du CIDOC CRM SIG) » a été posée le 2020-10-30, peu après le 48e CRM SIG dans le cadre de la publication d’un nouveau numéro sur le sujet. Les réponses à l’enquête ont été reçues jusqu’à la fin du mois de décembre 2020. Les réponses finales, non éditées, sur lesquelles ce rapport est basé, sont également disponibles ici.
Au total, 14 enquêtes ont été complétées. Sur les 14 questionnaires remplis, 11 étaient valides. Un des questionnaires remplis était un test et deux autres étaient des doublons. Bien que cela ne représente pas un jeu de données expansif, étant donné la taille de la communauté ayant des connaissances dans l’application des stratégies de graphes nommés et du CIDOC CRM, la taille de l’échantillon fournit probablement une image raisonnable des principales personnes mettant en application la norme CRM et des stratégies et applications de la technique des graphes nommés.
Dans ce rapport, le contenu de l’enquête, les réponses aux questions individuelles et quelques premières interprétations des résultats sont résumés. Les résultats de l’enquête sont proposés à la communauté du CRM SIG ainsi qu’aux personnes sondées afin d’ouvrir davantage la discussion et de rechercher des solutions communes aux possibilités et problèmes actuels et futurs dans l’application des graphes nommés aux données du patrimoine culturel encodées dans le CIDOC CRM.
Catégories de questions d’enquête et structure des questions
L’enquête est divisée en sept sections de questions :
- Approche générale
- Utilisation des graphes nommés pour l’agrégation
- Fonctions des graphes nommés
- Forme/limite des graphes nommés
- Graphes nommés et récupération de l’information
- Informations générales
- Données démographiques
Chacune des sections ci-dessus cible une série de questions permettant d’étoffer un sujet d’intérêt. Des descriptions plus précises de la signification de chaque section se trouvent ci-dessous. Les questions étaient généralement posées par paires, où les réponses analytiques (quantitatives) avec des catégories de réponses probables (booléennes, listes) étaient associées à des questions qualitatives descriptives qui permettaient aux personnes répondant à l’enquête de fournir des réponses plus détaillées et libres. Cette méthode a été adoptée afin d’obtenir des données comparables tout en laissant l’enquête ouverte pour fournir des résultats conformes à la pratique des personnes sondées si elle diffère des choix proposés. En outre, les catégories de réponses (booléennes, listes) étaient assorties d’une option « autre » afin de ne pas prédéterminer entièrement les réponses des personnes sondées.
Dans les sections ci-dessous, le rapport décrit le domaine d’analyse prévu pour chaque section, décrit les questions posées et indique les réponses analytiques tout en fournissant un résumé synthétique des réponses descriptives qui accompagnent ces résultats. Les données originales sont fournies en annexe du présent rapport.
Après un résumé de l’enquête et de ses résultats par section, une analyse générale des réponses à l’enquête et à la question de leur application aux discussions en cours au RCIP concernant la stratégie à adopter dans la planification de son processus d’agrégation sont présentés.
1. Approche générale
La fonction de cette section est de déterminer l’approche générale des personnes sondées à l’égard des graphes nommés, en déterminant qu’elles ont effectivement adopté la technique du graphe nommé et de déterminer les raisons fondamentales de l’adoption de cette approche ainsi que les formats qu’elles utilisent pour la mettre en application.
Cette section comprend les questions suivantes :
- 1.a. Utilisez-vous des graphes nommés dans votre pratique de gestion des données sémantiques?
- Oui
- Non
- Autre
- 1.b. Décrivez, en résumé, les utilisations que vous faites des construits de graphes nommés dans votre pratique de la gestion des données sémantiques.
- 2.a. Quel format de graphe nommé utilisez-vous?
- Tri-X
- Tri-G
- N-Quad
- Autre
- 2.b. En ce qui concerne le point 2.a., qu’est-ce qui a motivé l’adoption de ce format?
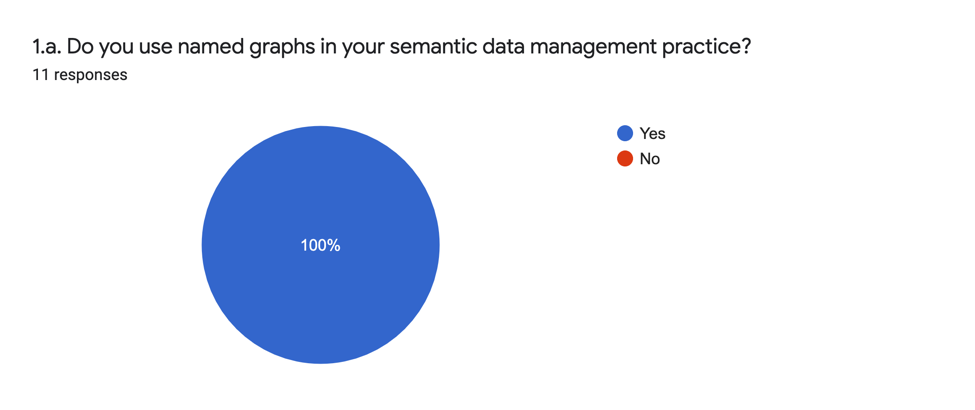
Question 1 : Utilisation des graphes nommés dans la gestion des données
La question 1 vise à comprendre l’approche globale des graphes nommés par la personne sondée.
Les réponses analytiques révèlent que toutes les institutions ayant répondu à l’enquête adoptent des graphes nommés dans leur pratique de gestion des données sémantiques.
| EN | FR |
|---|---|
| 1.a. Do you use named graphs in your semantic data management practice? | 1.a. Utilisez-vous des graphes nommés dans votre pratique de gestion des données sémantiques? |
| 11 responses | 11 réponses |
| Yes | Oui |
| No | Non |
Bien que les personnes sondées se soient sélectionnées elles-mêmes, l’omniprésence de cette réponse indique l’importance générale de cette technique dans la communauté.
La partie qualitative de la question (1.b.) demande aux personnes sondées de fournir les raisons pour lesquelles elles adoptent des graphes nommés dans leur travail. Les raisons invoquées pour l’adoption des graphes nommés sont diverses, mais peuvent être résumées par ordre de fréquence :
- Suivre la provenance des données;
- Distinguer ce qui constitue un « document »;
- Gérer les données en termes d’opérations CRUD;
- Séparer les types de données (p. ex. séparer l’ontologie des données).
La fonctionnalité permettant de fournir la provenance des données intégrées est la principale raison invoquée pour l’adoption des graphes nommés. Cette raison est suivie de près et est vaguement liée à la fonction d’utilisation du graphe nommé pour définir un « enregistrement » dans le sens d’une base de données classique. La notion d’« enregistrement » est fortement liée à la nécessité d’utiliser les graphes nommés pour gérer le graphe de données sémantiques au fil du temps, un enregistrement étant souvent assimilé à un jeu de données, soit dans son ensemble, soit en ce qui concerne ses parties initiales, tel que fourni et défini par un soumissionnaire de données. La création d’une unité d’enregistrement est liée à la troisième fonctionnalité établie par les personnes sondées : la gestion des données. Le graphe nommé en tant qu’enregistrement de provenance d’un soumissionnaire est une unité d’information qui peut être utilisée pour déterminer quelles données mettre à jour après un changement de soumissionnaire de données intégrées. Différentes organisations adoptent différents niveaux de division à cet égard, l’enregistrement étant défini tant au niveau du jeu de données du soumissionnaire qu’au niveau du document individuel considéré du côté de la source. Certains des systèmes d’information mentionnés pour la gestion des données sémantiques (p. ex. ResearchSpace) permettent/utilisent également le construit de graphes nommés pour la gestion interne des données, ce qui signifie que les graphes nommés sont adoptés par défaut lors du choix d’une solution technologique particulière. Le dernier point mentionné dans les réponses est l’utilisation de graphes nommés pour isoler des types de données spécifiques les uns des autres, comme l’ontologie elle-même des données qu’elle décrit.
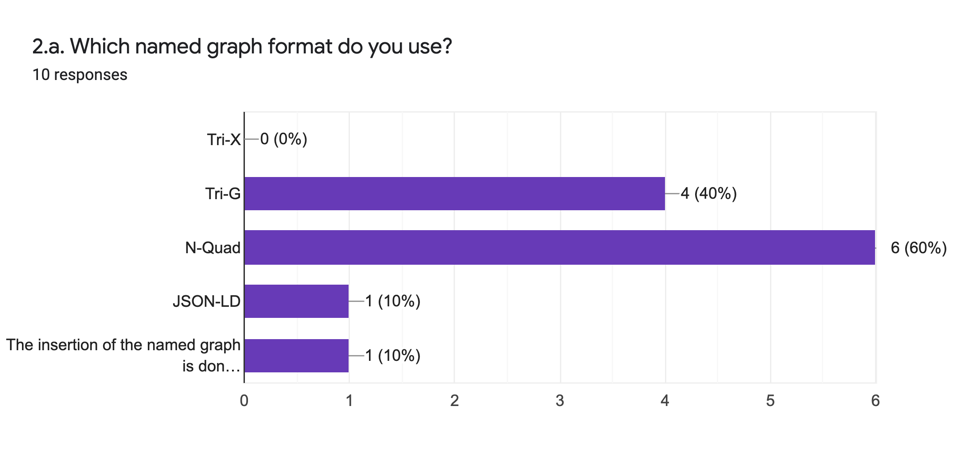
Question 2 : Format des graphes nommés
La question 2 vise à comprendre l’adoption actuelle de différents formats de graphes nommés pour la mise en application des graphes nommés et les motivations qui les sous-tendent.
Les réponses analytiques sont:
| EN | FR |
|---|---|
| 2.a. Which named graph format do you use? | 2.a. Quel format de graphe nommé utilisez-vous? |
| 10 responses | 10 réponses |
| Tri-X | Tri-X |
| Tri-G | Tri-G |
| N-Quad | N-Quad |
| JSON-LD | JSON-LD |
| The insertion of the named graph is don… | L’insertion du graphe nommé est don… |
Les réponses descriptives pour la motivation de l’adoption d’un format de graphe nommé particulier (2.b.) comprennent :
| Type | Raison |
|---|---|
| Général | lisibilité recommandation |
| N-Quad | chargement des données compact gestion des données facilité d’utilisation |
| Tri-G | lisibilité |
| JSON-LD | publication |
Nous pouvons conclure de ces résultats que le format le plus largement adopté est N-Quad, puisqu’il facilite les opérations de gestion des données, notamment le chargement des données. D’autres formats de graphes nommés sont utilisés à des fins de publication et pour faciliter la lisibilité. Étant donné que chaque format de graphe nommé fournit différentes actions possibles servant différentes fonctions, la motivation générale pour l’adoption d’un format particulier tend à suivre la fonction requise. Dans les résultats de l’enquête, l’accent est mis sur la fonctionnalité de la gestion des données, pour laquelle la tendance est de privilégier le format N-Quad.
2. Utilisation des graphes nommés pour l’agrégation
La fonction de cette section est de poser des questions portant spécifiquement sur l’utilisation des graphes nommés par les organisations dans leur processus d’agrégation.
Cette section comprend les questions suivantes :
- 3.a. Utilisez-vous des graphes nommés spécifiquement pour soutenir des processus d’agrégation de données?
- Oui
- Non
- Autre
- 3.b. (si 3.a. = oui) Décrivez, en résumé, votre utilisation des graphes nommés dans vos processus d’agrégation.
- 4.a. Pour les données ingérées d’un soumissionnaire de données, à quel niveau appliquez-vous les graphes nommés?
- Jeu de données complet
- Niveau d’enregistrement
- Jeu de données complet et niveau d’enregistrement
- Autre
- 4.b. Décrivez pourquoi vous avez choisi d’adopter ce niveau pour l’utilisation des graphes nommés dans votre processus d’agrégation.
- 5.a. À quel moment dans votre processus d’agrégation de données/stratégie ETC (extraire, transformer, charger) appliquez-vous les graphes nommés?
- 5.b. Dans votre processus de mise à jour de l’agrégation, quelle est l’unité de mise à jour?
- Jeu de données complet
- Niveau d’enregistrement
- Partie d’enregistrement
- Autre
- 5.c. Comment votre politique de graphe nommé prend-elle en charge le processus de mise à jour de l’agrégation?
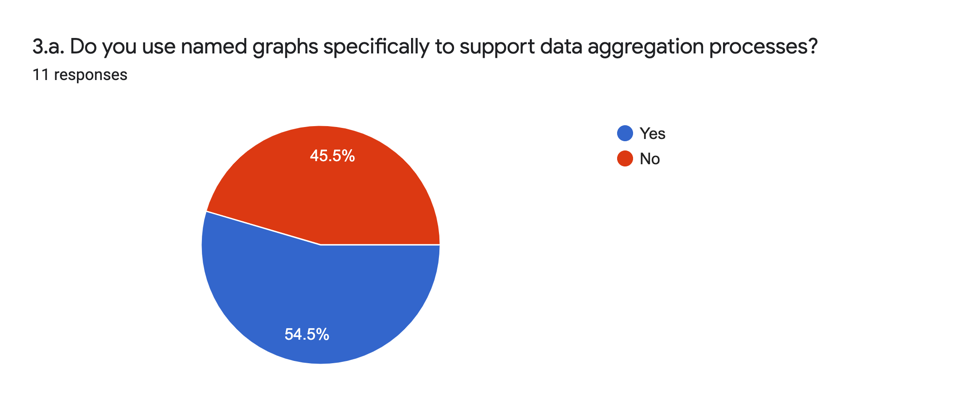
Question 3 : Utilisation de graphes nommés dans les processus d’agrégation
La question 3 vise à comprendre dans quelle mesure les graphes nommés sont spécifiquement adoptés dans le but de soutenir les processus d’agrégation de données.
La réponse analytique à cette question (3.a.) est la suivante :
| EN | FR |
|---|---|
| 3.a. Do you use named graphs specifically to support data aggregation processes? | 3.a. Utilisez-vous des graphes nommés spécifiquement pour soutenir les processus d’agrégation de données? |
| 11 responses | 11 réponses |
| Yes | Oui |
| No | Non |
Une faible majorité de personnes sondées indiquent qu’elles utilisent des graphes nommés à des fins d’agrégation de données. Celles ayant répondu par l’affirmative indiquent dans leurs réponses longues (3.b.) que les graphes nommés ont pour fonction d’identifier la provenance des informations d’un soumissionnaire et de gérer les opérations CRUD (Create, Read, Update, Delete).
Il y a un décalage intéressant entre cette question et les questions suivantes de cette section. Alors qu’un peu plus de la moitié des personnes sondées indiquent qu’elles utilisent des graphes nommés dans le but spécifique de l’agrégation, la majorité ont continué de répondre aux autres questions de cette section. Parmi les raisons de ce décalage, deux scénarios sont possibles : une mauvaise structuration de l’enquête (les personnes sondées avaient l’impression qu’elles devaient répondre aux questions suivantes) ou un décalage dans la compréhension du concept d’agrégation. Dans le premier cas, il est possible que les personnes sondées aient cru que leur seule occasion de parler de la division des jeux de données se présenterait dans cette section, ce qui explique pourquoi elles ont choisi d’y répondre ici. Dans le second cas, il est possible que les personnes sondées soient parties d’un sens strict de l’agrégation (c.à-d. agir comme un agrégateur) pour arriver à un sens plus large d’intégration des données dans un réseau sémantique. D’autres explications peuvent également être valables. Quoi qu’il en soit, les réponses qui suivent restent instructives sur la question générale de la structuration des données dans les processus d’agrégation et sont donc conservées comme telles.
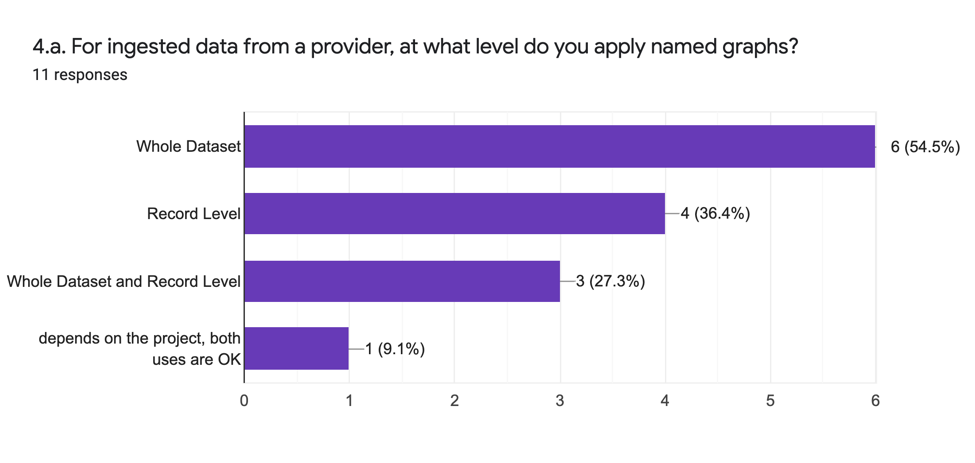
Question 4 : Niveau d’application des graphes nommés
La question 4 vise à comprendre le niveau de granularité utilisé dans l’application des graphes nommés dans le processus d’agrégation. Ici, les réponses analytiques résultantes (4.a.) sont les suivantes :
| EN | FR |
|---|---|
| 4.a. For ingested data from a provider, at what level do you apply named graphs? | 4.a. Pour les données ingérées d’un soumissionnaire, à quel niveau appliquez-vous les graphes nommés? |
| 11 responses | 11 réponses |
| Whole Dataset | Jeu de données complet |
| Record Level | Niveau d’enregistrement |
| Whole Dataset and Record Level | Jeu de données et niveau d’enregistrement |
| Depends on the project, both uses are OK | Cela dépend du projet, les deux utilisations sont acceptables |
Les réponses analytiques indiquent que de multiples stratégies sont adoptées, incluant l’utilisation du graphe nommé à la fois au niveau du jeu de données, au niveau de l’enregistrement ainsi qu’un mélange des deux.
Les motivations pour l’adoption des stratégies ci-dessus, telles que décrites dans les réponses qualitatives (4.b.), peuvent être résumées comme suit :
Jeu de données complet :
Il existe une tendance générale à considérer le niveau du jeu de données comme un niveau de granularité suffisant pour traiter les jeux de données externes. Une plus grande granularité de représentation n’est pas considérée comme nécessaire à des fins de gestion des données et les inconvénients de la mise en application d’une acquisition plus précise au niveau de l’enregistrement sont considérés comme prohibitifs. La limitation de la stratégie des graphes nommés au niveau des jeux de données peut également être affectée par les outils disponibles. Certains logiciels, tant pour la transformation que pour la gestion des données, ne prennent en charge que la démarcation de l’ensemble d’un jeu de données et le choix est donc induit de l’externe. Certaines personnes sondées indiquent qu’elles souhaitent passer au niveau de l’enregistrement, tandis que d’autres indiquent que les implications pratiques de la quantité massive de données créées par l’application de la documentation au niveau de l’enregistrement ne valent pas la dépense par rapport à la nécessité d’une mise à jour au niveau granulaire.
Niveau de l’enregistrement :
Les graphes nommés au niveau de l’enregistrement sont considérés comme généralement souhaitables par les personnes sondées les ayant adoptés. Ce caractère souhaitable découle à la fois de la nécessité d’une mise à jour individuelle, mais aussi de la possibilité de publier des enregistrements individuels cohérents et récupérables par l’entremise d’une API. Cela dit, la capacité de mise en application dépend fortement des environnements de mise en application. Lorsque l’environnement de mise en application permet l’adoption de graphes nommés au niveau de l’enregistrement, ceux-ci ont tendance à être adoptés en conséquence de cette capacité, mais la fonction d’utilisation de graphes nommés au niveau du jeu de données pour l’agrégation des données persiste.
Jeu de données et niveau de l’enregistrement :
La motivation derrière une stratégie de niveau mixte est la reconnaissance de besoins différents pour des projets différents. La mise en place d’environnements comme ResearchSpace, qui exigent essentiellement l’adoption de graphes nommés aux deux niveaux, encourage l’adoption d’une stratégie de mixité.
Question 5 : Processus de point d’application des graphes nommés
La question 5 vise à comprendre comment la stratégie du graphe nommé dans un processus d’agrégation de données est mise en application.
La première partie (5.a.) demande à quel stade du processus d’agrégation les graphes nommés sont appliqués.
Les réponses peuvent être classées comme suit :
- Lors de la création des données : dans une stratégie où la sémantique fait partie des premiers processus, les données sont générées dès le départ avec leur graphe nommé;
- À l’ingestion : les données RDF sont associées à un graphe nommé au moment de l’importation dans le système;
- À l’exportation : dans les systèmes prenant en charge l’exportation vers une structure de données sémantiques, l’information relative au graphe nommé est ajoutée au moment de l’exportation;
- Lors de la transformation des données : dans une stratégie ETC (extraire, transformer, charger) de données sémantiques, les données sont ajoutées par le logiciel de traitement de la transformation.
En général, les réponses indiquent que les graphes nommés peuvent être générés à différents moments du processus de données, en fonction du projet, de la nature sémantique ou non des données sources et du logiciel particulier adopté.
La deuxième partie (5.b.) demande de manière analytique quelle est l’unité de mise à jour pour les enregistrements agrégés, avec les résultats suivants :
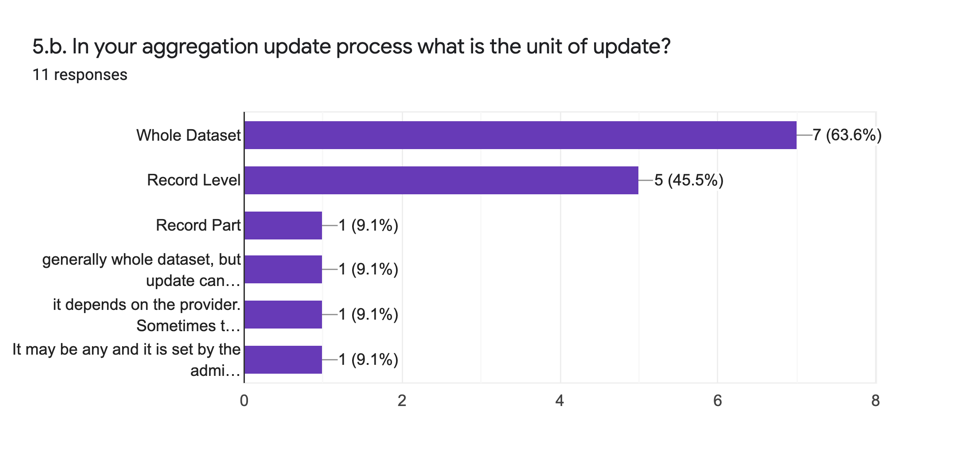
| EN | FR |
|---|---|
| 5.b. In your aggregation update process what is the unit of update? | 5.b. Dans votre processus de mise à jour de l’agrégation, quelle est l’unité de mise à jour? |
| 11 responses | 11 réponses |
| Whole Dataset | Jeu de données complet |
| Record Level | Niveau de l’enregistrement |
| Record Part | Partie de l’enregistrement |
| Generally whole dataset, but update can… | Généralement le jeu de données, mais la mise à jour peut… |
| It depends on the provider. Sometimes t… | Cela dépend du soumissionnaire. Parfois… |
| It may be any and it is set by the admi… | Il peut être quelconque et il est établi par l’admi.. |
Nous pouvons voir que ces réponses ressemblent beaucoup aux réponses à la question 4.a. L’unité de mise à jour tend à être un jeu de données entier, mais certains mettent en application des mises à jour au niveau de l’enregistrement si leur logiciel de mise en application le permet. En général, la décision est pragmatique et liée au besoin du projet pour la granularité de la mise à jour. Il y a un compromis entre la précision du niveau de l’enregistrement et la complexité qu’il apporte.
La dernière partie de cette question (5.c.) demande comment la politique de graphe nommé soutient l’effort d’agrégation de la personne sondée.
La réponse la plus fréquente est qu’elle permet à la personne sondée de recharger les données d’un soumissionnaire au niveau d’un jeu de données ou d’un enregistrement dans un processus géré sans conséquences involontaires sur d’autres jeux de données agrégées. L’intention de la question était de s’enquérir d’une politique explicite en matière de graphes nommés que la personne sondée aurait pu adopter et de comprendre si cette adoption explicite d’une telle politique était d’un soutien particulier dans le processus d’agrégation des données. Les réponses à la question indiquent que celle-ci a été mal formulée ou que la notion de politique de graphe nommé en soi n’est généralement pas clairement définie dans les projets.
3. Fonctions des graphes nommés
Cette section vise à explorer plus généralement les autres fonctions, autres que l’agrégation, pour lesquelles la personne sondée utilise des graphes nommés et à comprendre de quelle manière elle le fait.
Cette section comprend les questions suivantes :
- 6.a. Pour laquelle, le cas échéant, des fonctionnalités suivantes utilisez-vous des graphes nommés?
- Enregistrement de la provenance
- Opérations CRUD
- Argumentation/Inférence
- Appariement d’entités
- Autre
- 6.b. Si vous utilisez des graphes nommés pour retracer l’information de provenance, à quel niveau appliquez-vous l’information de provenance et à quelle étape de votre processus d’intégration?
- 6.c. Si vous utilisez des graphes nommés pour supporter les processus CRUD, quel niveau de support des opérations CRUD supportez-vous avec cette méthode? Comment la stratégie de graphe nommé que vous avez choisie permet-elle ce niveau d’opérations CRUD?
- 6.d. Si vous utilisez des graphes nommés pour soutenir une argumentation ou une documentation d’inférence, de quel type d’argumentation ou d’inférence s’agit-il? Appliquez-vous CRMinf? Comment la stratégie de graphe nommé que vous avez choisie permet-elle ce travail?
- 6.e. Si vous utilisez des graphes nommés pour prendre en charge la correspondance des entités, comment déployer les graphes nommés afin de séparer les données générées des données initiales?
Question 6 : Autres fonctions/applications des graphes nommés
L’objectif de la question 6 est de comprendre les différentes fonctions auxquelles les graphes nommés sont appliqués dans la pratique.
Les réponses analytiques à cette question (6.a.) sont les suivantes :
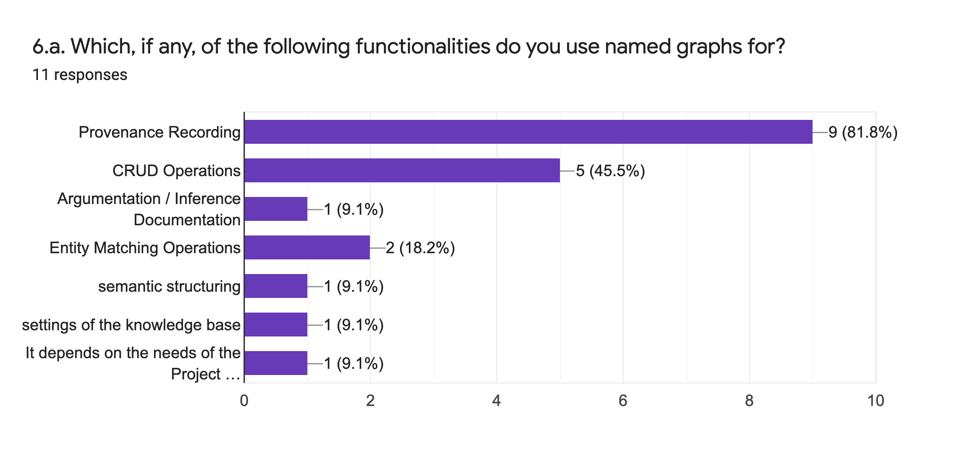
| EN | FR |
|---|---|
| 6.a. Which, if any, of the following functionalities do you use named graphs for? | 6.a. Pour laquelle, le cas échéant, des fonctionnalités suivantes utilisez-vous des graphes nommés? |
| 11 responses | 11 réponses |
| Provenance Recording | Enregistrement de la provenance |
| CRUD Operations | Opérations CRUD |
| Argumentation/Inference Documentation | Documentation sur l’argumentation/l’inférence |
| Entity Matching Operations | Opérations de correspondance d’entités |
| Semantic structuring | Structuration sémantique |
| Settings of the knowledge base | Paramètres de la base de connaissances |
| It depends on the needs of the Project… | Cela dépend des besoins du projet… |
Le graphique ci-haut indique que l’utilisation massive du graphe nommé est pour des fins d’enregistrement de la provenance des données, suivie des opérations CRUD. Une seule personne sondée indique qu’elle utilise les graphes nommés pour documenter l’argumentation et deux indiquent qu’elles les utilisent pour la correspondance des entités. Les options ajoutées indiquent que les graphes nommés sont également adoptés pour contrôler les paramètres de la base de connaissances elle-même et pour la « structuration sémantique » (dont la signification n’est pas claire dans le contexte).
Les questions qualitatives de suivi du point 6.a. (6.b. - 6.e.) visent à isoler plus de détails sur les utilisations particulières de la technique du graphe nommé.
Voici un résumé de l’intention de ces réponses :
Enregistrement de la provenance (6.b.) : cette question demande à quel niveau l’information sur la provenance est appliquée et à quelle étape du processus d’intégration. Les réponses peuvent être divisées comme suit :
- Niveau d’utilisation a. Jeu de données complet b. Enregistrement
- Métadonnées ajoutées a. Aucunes, utilise simplement l’URI b. Métadonnées simples c. Nom du soumissionnaire
- Temps ajouté a. Au moment de la transformation dans le logiciel b. Au moment de l’intégration c. Pendant la création
Cette question est surchargée en termes d’informations qu’elle cherche à récupérer et recoupe en partie la question 5. Cela dit, elle fournit une confirmation supplémentaire de la variété des approches adoptées pour l’application des données de provenance. Les variables de mise en application sont significativement affectées par les objectifs du projet et la mise en application du logiciel.
Là encore, les métadonnées sont ajoutées à un graphe nommé soit au niveau du jeu de données, soit au niveau de l’enregistrement, en fonction de la granularité souhaitée et de la capacité des outils adoptés à prendre en charge les graphes nommés au niveau de l’enregistrement.
Les métadonnées ajoutées aux graphes nommés générés vont d’aucune autre que l’URI du graphe lui-même, au nom du soumissionnaire, en passant par une « métadonnée simple » non définie.
La durée du processus d’ajout de ces métadonnées dépend fortement du type de projet et du logiciel utilisé. Certains logiciels de transformation permettent d’ajouter les métadonnées du graphe nommé au cours du processus de transformation. Les plateformes de gestion de données sémantiques référencées offrent également la possibilité de préciser les métadonnées du graphe nommé au moment de l’intégration. Dans le contexte de données sémantiquement générées, les informations des métadonnées du graphe nommé peuvent être ajoutées au moment de la création.
Opérations CRUD (6.c.) : Cette question demande à la personne sondée d’indiquer quelles opérations CRUD sa stratégie de graphe nommé prend en charge. L’ensemble des réponses est réduit, l’éventail des réponses étant le suivant :
- CRUD
- R/D
- C/R/D
Les utilisations faites du graphe nommé dans ce cas semblent dépendre fortement des capacités du logiciel de gestion des données sémantiques adopté.
Argumentation/Inférence (6.d.) : Cette question découle spécifiquement du contexte du CIDOC CRM de l’enquête et se rapporte à la norme CRMinf, qui suggère l’utilisation de graphes nommés dans le contexte du traçage de l’argumentation sur les connaissances documentées en triplets. Cette question n’a suscité qu’une seule réponse indiquant que cette fonctionnalité est mise en application dans ResearchSpace.
Correspondance d’entités (6.e.) : Cette question vise à comprendre si les graphes nommés sont utilisés pour stocker séparément les données générées lors des processus de correspondance d’entités. Deux réponses indiquent que cette approche a été adoptée et que toutes les données d’enrichissement créées à partir des processus de correspondance des entités sont insérées dans des graphes nommés séparés afin de distinguer les données générées des données sources.
4. Forme/limite des graphes nommés
Cette section vise à explorer la question des « formes » ou des « limites » des graphes nommés, en particulier les critères adoptés par les personnes sondées pour déterminer ce qui doit ou ne doit pas faire partie d’un graphe nommé et si cette politique est officielle ou ad hoc.
Cette section comprend les questions suivantes :
- 7.a. Avez-vous une politique explicite en matière de forme/limite des graphes nommés?
- Oui
- Non
- Autre
- 7.b. Décrivez, en résumé, votre stratégie de forme/limite des graphes nommés et pourquoi vous l’avez adoptée.
- 8.a. Lorsque vous spécifiez des formes/limites de graphes nommés, quelles sont les règles suivantes (s’il y a lieu) que vous suivez?
- Limite du jeu de données du soumissionnaire de données
- Limite de l’enregistrement du soumissionnaire de données
- Limite du jeu de données définie par l’agrégateur
- Limite de l’enregistrement définie par l’agrégateur
- Autre
- 8.b. En ce qui concerne la question 8.a., expliquez pourquoi vous avez choisi de mettre en application ces options et comment.
Question 7 : Politique des graphes nommés
La question 7 vise à explorer l’adoption de politiques explicites de graphes nommés par la personne sondée.
Les réponses analytiques (7.a.) sont les suivantes :
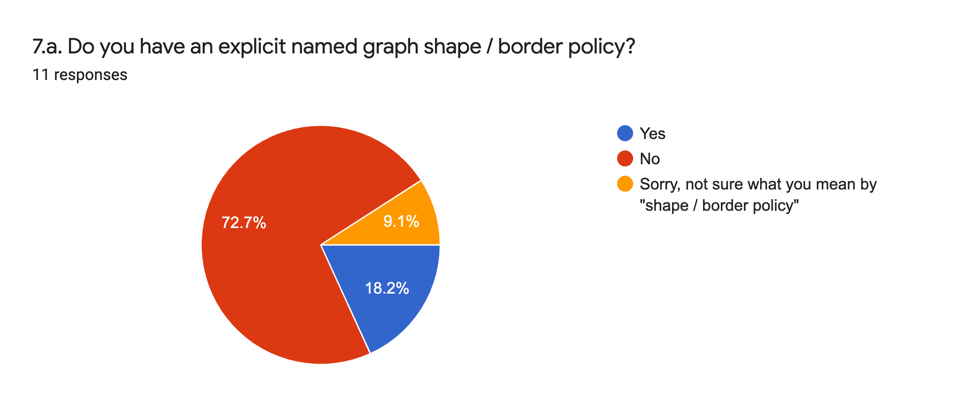
| EN | FR |
|---|---|
| 7.a. Do you have an explicit named graph shape/border policy? | 7.a. Avez-vous une politique explicite en matière de forme/limite de graphes nommés? |
| 11 responses | 11 réponses |
| Yes | Oui |
| No | Non |
| Sorry, not sure what you mean by “shape/border policy” | Désolé, je ne suis pas sûr·e de ce que vous voulez dire par « politique en matière de forme/limite ». |
Les réponses analytiques et qualitatives (7.b.) indiquent que la spécification explicite d’une politique de graphe nommé pour ce qui est au sein ou en dehors d’un graphe nommé n’est pas une pratique largement adoptée. Là encore, la tendance est de considérer la désignation des graphes nommés comme une partie fonctionnelle de la gestion des données sémantiques plutôt que comme faisant partie des données sémantiques elles-mêmes. Les exceptions à cette réponse générale sont l’adoption du modèle linked.art et l’indication qu’il s’agit d’un résultat souhaité pour certains projets.
Question 8 : Paramètres de définition des graphes nommés
La question 8 porte sur l’origine de la politique de graphe nommé, qu’elle soit implicite ou explicite.
Les réponses analytiques (8.a.) sont les suivantes :
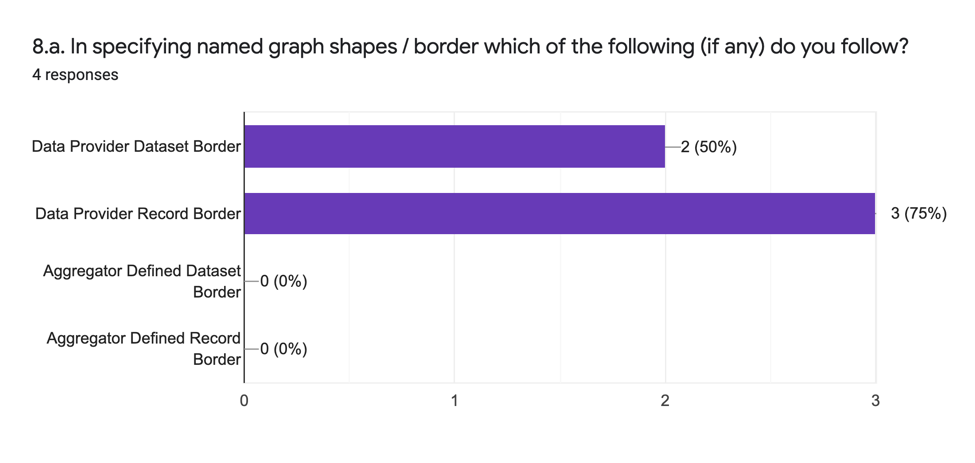
| EN | FR |
|---|---|
| 8.a. In specifying named graph shapes/borders, which of the following (if any) do you follow? | 8.a. Lorsque vous spécifiez des formes/limites de graphes nommés, quelles sont les règles suivantes (s’il y a lieu) que vous suivez? |
| 4 responses | 4 réponses |
| Data Provider Dataset Border | Limite du jeu de données du soumissionnaire de données |
| Data Provider Record Border | Limite de l’enregistrement du soumissionnaire de données |
| Aggregator Defined Dataset Border | Limite du jeu de données définie par l’agrégateur |
| Aggregator Defined Record Border | Limite de l’enregistrement définie par l’agrégateur |
Les réponses analytiques et qualitatives (8.b.) indiquent que la tendance générale est d’utiliser des graphes nommés pour refléter la structure des données du soumissionnaire telles qu’elles sont fournies plutôt que d’utiliser un nouveau construit fourni par l’agrégateur.
5. Graphes nommés et récupération de l’information
Cette section vise à établir de quelle manière, le cas échéant, les graphes nommés sont utilisés pour soutenir la fonction de récupération de l’information à partir du réseau de données sémantiques.
Cette section comprend les questions suivantes :
- 9.a. Utilisez-vous des graphes nommés dans votre processus de récupération de l’information pour les entités individuelles d’intérêt dans le graphe de connaissances?
- Oui
- Non
- Autre
- 9.b. Comment récupérez-vous toute l’information relative à une seule entité d’intérêt (p. ex. un actant, un monument), en combinant ou en séparant les informations provenant de diverses sources de données?
Question 9 : Fonctionnalité des graphes nommés et des requêtes
La question 9 vise à s’enquérir de l’utilisation de graphes nommés pour soutenir la récupération de l’information.
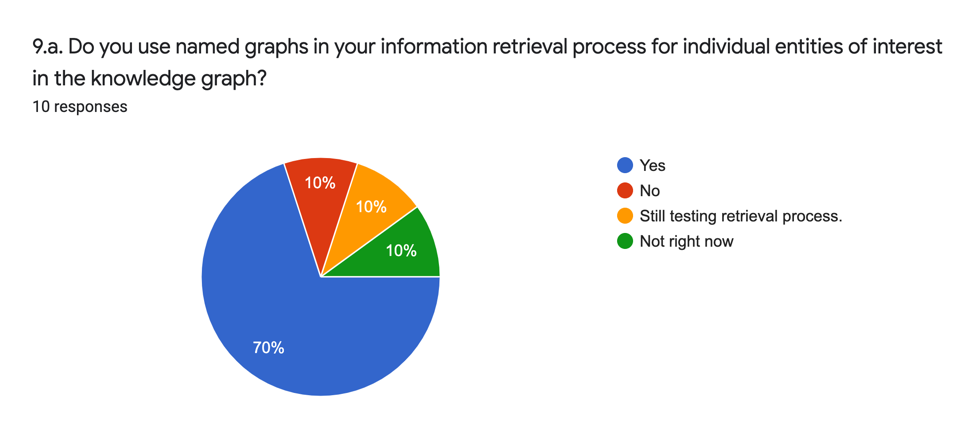
Les réponses analytiques (9.a.) sont les suivantes :
| EN | FR |
|---|---|
| 9.a. Do you use named graphs in your information retrieval process for individual entities of interest in the knowledge graph? | 9.a. Utilisez-vous des graphes nommés dans votre processus de récupération de l’information pour les entités individuelles d’intérêt dans le graphe de connaissances? |
| 10 responses | 10 réponses |
| Yes | Oui |
| No | Non |
| Still testing retrieval process | Je teste encore le processus de récupération |
| Not right now | Pas pour le moment |
Comme l’indiquent les réponses analytiques, la majorité des personnes sondées utilisent, sous une forme ou une autre, le graphe nommé dans la recherche d’information.
La description qualitative (9.b.) permet de mieux comprendre le fonctionnement. Ici, l’intention de la question est de comprendre si les graphes nommés ou d’autres méthodes sont utilisés afin de récupérer l’ensemble de l’information concernant une entité particulière.
Les réponses des personnes sondées peuvent être classées comme suit :
- Mettre la connaissance agrégée dans son propre graphe nommé : un nouveau graphe nommé avec la connaissance concaténée est généré;
- Concaténation SPARQL : une requête complexe tirant de l’information de toutes les sources différentes est créée;
- Recherche d’un graphe nommé individuel : l’agrégation n’est pas effectuée, les différentes sources sont présentées séparément;
- Modèles/Formulaires/API : la politique des limites de l’entité est techniquement définie par l’entremise des modèles d’accès à l’entité, que ce soit pour la saisie ou la récupération de données.
Cette question n’est pas aussi clairement définie qu’elle aurait dû l’être et demande aux personnes sondées de répondre à trop de questions à la fois. Néanmoins, les résultats sont intéressants. Des stratégies complètement différentes sont proposées et mises en application, allant de la génération d’un graphe nommé intégré distinct pour les connaissances agrégées à la génération de requêtes complexes sans intégration. Les concepts de modèles et d’API mentionnés dans certaines réponses semblent indiquer la mise en application d’une politique de limite de graphe nommé dans la pratique, mais sans spécification explicite documentée.
6. Informations générales
Cette section permet à la personne sondée de fournir des informations qualitatives supplémentaires concernant son utilisation des graphes nommés.
Cette section comprend les questions suivantes :
- 10. Veuillez indiquer, si vous le souhaitez, toute information ou question supplémentaire que vous avez concernant l’utilisation de graphes nommés dans le cadre de la communauté du CIDOC CRM et en ce qui concerne la tâche d’agrégation des données.
- 11. Pouvez-vous mentionner des projets ou des propositions d’intérêt particulier en ce qui concerne la question de l’application des graphes nommés dans la communauté du CIDOC CRM?
- 12. Texte libre, n’hésitez pas à ajouter tout commentaire ou toute information supplémentaire que vous jugez important d’enregistrer dans le cadre de la réflexion sur les meilleures pratiques en matière d’utilisation de graphes nommés pour la création et la maintenance de données sémantiques patrimoniales canadiennes.
Question 10 : Informations supplémentaires
Cette question permet aux personnes sondées d’indiquer les principales questions ou préoccupations auxquelles, selon elles, la communauté du CIDOC CRM est confrontée dans l’utilisation des graphes nommés. De manière synthétique, les réponses incluent :
- Limites de l’utilisation de quadruplets dans des contextes de graphes nommés multiples;
- Limitation de quadruplets en termes de capacité d’interrogation;
- Absence de directives centrales pour l’adoption.
Question 11 : Projets et logiciels d’importance
Cette question demande à la personne sondée de mentionner des projets d’intérêt qui devraient être pris en compte par la communauté du CIDOC CRM dans la recherche de la mise en application pratique des graphes nommés. De manière synthétique, les réponses incluent :
- Arches
- Neptune
- RDF*
- SPARQL*
- Projet Pharos
- Projet PARTHENOS
- ARIADNEPlus
- WissKI
Question 12 : Adéquation de l’enquête
Cette question invite les personnes sondées à commenter l’enquête et son adéquation à la question posée. Il y a eu peu de réponses, résumées comme suit :
- Certaines questions de l’enquête sont trop générales ou trop vagues;
- L’enquête a bien été menée.
7. Données démographiques
Cette section demande des informations démographiques anonymes afin de contextualiser les réponses des personnes sondées en fonction du type d’institution/d’actant qui répond.
Cette section comprend les questions suivantes :
- 0.a Type d’organisation
- Université
- Institut de recherche
- Soumissionnaire de données
- Producteur·rice de données
- Soumissionnaire de logiciels
- Prestataire de services
- 0.b Utilisation de/Relation avec les données sémantiques par l’organisation
- 0.c J’accepte la réutilisation de ces données sous une licence CC0
Question 0 : Données démographiques
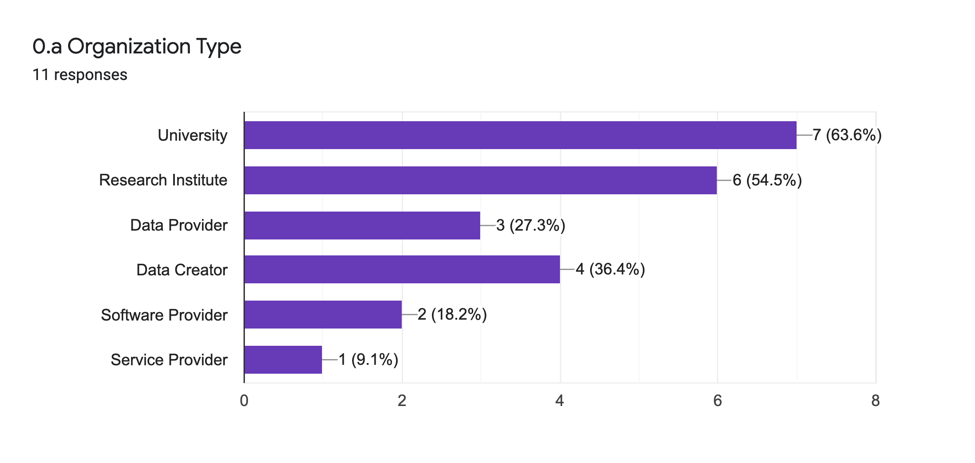
La première partie de cette question (0.a.) cherche à établir le type d’institution de l’organisation pour laquelle la personne sondée a participé à l’enquête. Les réponses sont les suivantes :
| EN | FR |
|---|---|
| 0.a. Organization Type | 0.a. Type d’organisation |
| 11 responses | 11 réponses |
| University | Université |
| Research Institute | Institut de recherche |
| Data Provider | Soumissionnaire de données |
| Data Creator | Producteur·rice de données |
| Software Provider | Soumissionnaire de logiciels |
| Service Provider | Prestataire de services |
Les environnements universitaires et de recherche, ainsi que les producteurs·rices et soumissionnaires de données sont largement représentés. La question ne comporte pas de choix pour l’agrégateur de données ou toute autre option, ce qui représente une erreur dans la formulation de l’enquête. On peut déduire des réponses de la section deux que ces fonctions sont également représentées dans l’échantillon de l’enquête.
La deuxième partie de cette question demande une description qualitative des utilisations des données sémantiques dans l’organisation. De manière synthétique, les réponses reçues comprennent :
- Promotion des données liées;
- Liaison des données patrimoniales canadiennes à travers les institutions de mémoire;
- Production de données;
- Développement de logiciels sémantiques;
- Domaines d’intervention : archéologie et linguistique.
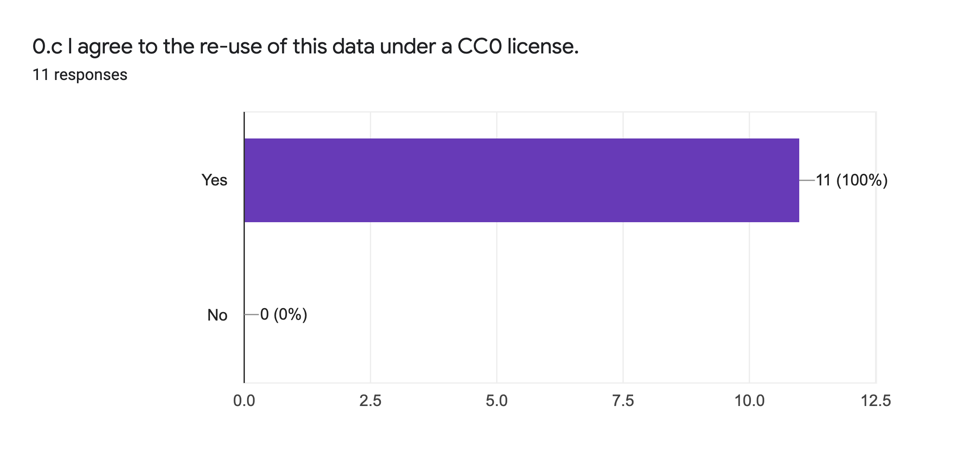
La dernière question de l’enquête demande aux personnes sondées si elles acceptent que les données de leurs réponses soient partagées sous une licence CC0. Cette proposition est acceptée à l’unanimité :
| EN | FR |
|---|---|
| 0.c. I agree to the re-use of this data under a CC0 license. | 0.c. J’accepte la réutilisation de ces données sous une licence CC0. |
| 11 responses | 11 réponses |
| Yes | Oui |
| No | Non |
Discussion sur les résultats de l’enquête générale
L’enquête donne un aperçu général de l’état actuel de l’utilisation des graphes nommés dans la communauté du CIDOC CRM. L’enquête vise à répondre à des questions très générales sur la façon dont les graphes nommés sont utilisés dans cette communauté. En particulier, l’objectif était de comprendre :
Dans quelle mesure les graphes nommés sont-ils utilisés et sous quel format?
Bien que l’enquête soit adressée spécifiquement aux membres de la communauté du CIDOC CRM intéressés par les graphes nommés, les réponses fournies dans cette enquête soutiennent la conclusion générale que les graphes nommés sont largement utilisés par cette communauté. Si l’utilité ou la nécessité d’adopter des graphes nommés dans la pratique de la gestion des données sémantiques avait été controversée ou avait fait l’objet d’un désaccord majeur, il aurait été probable qu’il y ait au moins quelques personnes sondées se sélectionnant elles-mêmes qui contestent l’application de cette technique. L’absence de telles réponses dans une enquête ouvertement publiée suggère qu’un tel positionnement n’existe pas ou qu’il soit minoritaire.
Les graphes nommés sont utilisés comme cheval de bataille dans la pratique de la gestion des données sémantiques dans les systèmes CRM, en grande partie pour prendre en charge l’ingestion et la mise à jour de données provenant de soumissionnaires. L’adoption d’un format est largement déterminée par des questions pragmatiques d’utilité par rapport à la fonction, la fonction la plus courante étant de permettre l’agrégation et la mise à jour cohérentes des données.
Comment les graphes nommés sont-ils appliqués spécifiquement dans le contexte de l’agrégation?
Les résultats de la section de l’enquête portant spécifiquement sur l’utilisation des graphes nommés sont quelque peu ambigus dans la mesure où les réponses globales indiquent que seule une faible majorité utilise les graphes nommés pour soutenir spécifiquement les processus d’agrégation, alors que l’ensemble de la section soit bien remplie, quoi qu’il en soit, de réponses. Cela est probablement dû au fait que les personnes sondées assimilent formellement l’agrégation à la notion de jouer le rôle d’un agrégateur, alors que dans un sens plus général, elle peut être considérée comme une intégration d’informations.
L’adoption de graphes nommés est considérée comme essentielle pour la pratique des agrégateurs de données sémantiques, leur permettant d’attribuer une provenance à leurs données et de gérer les mises à jour.
En ce qui concerne la création de graphes nommés, il y a une nette tendance à suivre la forme des données telles que fournies par le soumissionnaire. Il existe toujours une tendance générale à l’attribution des graphes nommés au niveau du jeu de données plutôt qu’au niveau de l’enregistrement. Les raisons à cela peuvent être la perception que le gain en termes de granularité dans l’adoption d’une politique de graphe nommé au niveau de l’enregistrement soit compensé par la surcharge informationnelle du système, ainsi que le manque d’outils capables de mettre en application une politique davantage granulaire. Les adoptants des stratégies de graphes nommés au niveau de l’enregistrement sont enthousiastes quant à leur utilité pour soutenir les processus de mise à jour et leur flexibilité générale. On peut constater que l’adoption de stratégies au niveau de l’enregistrement est considérablement affectée par les choix technologiques de la personne effectuant cette adoption. Compte tenu des descriptions de nombreuses personnes sondées, les personnes utilisant les plateformes Metaphact et ResearchSpace, qui emploient toutes deux nativement des graphes nommés et facilitent donc directement une approche plus précise, étaient relativement nombreuses.
La tendance à suivre la distinction de niveau d’enregistrement du soumissionnaire, lorsqu’elle est disponible, soulève la question de comment gérer ces différentes limites de niveau de l’enregistrement à long terme.
Quelles sont les autres applications des graphes nommés?
Bien que l’enquête porte sur une série d’applications auxquelles les graphes nommés sont potentiellement applicables dans le CIDOC CRM mettant en application des jeux de données sémantiques patrimoniales canadiennes, l’utilisation dominante du graphe nommé est pratique et concerne la prise en charge de la provenance et des opérations CRUD. Des utilisations supplémentaires avancées, telles que le soutien et la distinction des opérations de mise en correspondance des entités ou la documentation de l’argumentation, ne sont pas des applications courantes des graphes nommés pour les personnes sondées. La perception des graphes nommés comme étant un outil pratique permettant de séparer les données d’entrée du soumissionnaire et d’assurer des mises à jour harmonieuses l’emporte sur les autres applications potentielles de la méthode des graphes nommés. Quelles sont les politiques définies pour l’utilisation des graphes nommés?
Les réponses à cette question explicite et aux références implicites à celle-ci dans d’autres questions semblent sous-entendre une lacune dans la réflexion sur la politique de graphe nommé. L’idée d’une politique de graphe nommé semble être étrangère à la plupart des personnes sondées. On peut probablement attribuer cela au fait que les graphes nommés ne soient pas considérés comme une partie des données sémantiques elles-mêmes, mais comme une méthode pratique en dehors du contenu pour gérer les trousses d’information. Seul le modèle linked.art est mentionné explicitement comme ayant développé/développant une politique de graphe nommé. Toutefois, étant donné le rôle important que les graphes nommés jouent dans le cycle de vie de la gestion des données sémantiques selon l’enquête, il peut être conclu qu’il y a là une ouverture significative pour l’élaboration de lignes directrices pour la formulation et l’explicitation de telles politiques. Ces travaux pourraient également prendre en compte et mettre en évidence des utilisations plus complexes des graphes nommés pour des travaux tels que la mise en correspondance d’entités et l’argumentation, qui se trouvent sans doute en marge de l’utilisation en raison d’un manque de définition formelle explicite de leur application.
Les politiques de graphe nommé semblent être pertinentes, que les limites reposent sur la structure du soumissionnaire ou de l’agrégateur. Dans les deux cas, il est important de définir ce que l’on peut trouver dans le graphe nommé et comment récupérer les informations appropriées. D’une part, si la base de connaissances contient plusieurs structures de données provenant de différents soumissionnaires, les personnes l’utilisant doivent comprendre les similitudes et la manière de générer des requêtes fédérées. D’autre part, si l’agrégateur fait correspondre les données de ses soumissionnaires à une structure unique de données/d’enregistrement, les personnes l’utilisant doivent comprendre quels changements ont été apportés afin de retrouver ce qu’elles ont l’habitude de trouver normalement dans le jeu de données du soumissionnaire.
Quelle fonction les graphes nommés jouent-ils dans les stratégies de récupération de l’information?
Les résultats de cette question sont révélateurs du fait de l’absence de consensus. Bien que la majorité des personnes répondant à l’enquête aient indiqué que le graphe nommé est utilisé d’une manière ou d’une autre dans le processus de récupération de l’information, la manière dont il l’est est totalement différente. Il peut être conclu qu’ici aussi, le manque de lignes directrices formelles et d’explicitation des politiques relatives aux graphes nommés a un effet limitatif important sur leur adoption pratique, notamment à des fins de récupération de l’information.
Il semble pertinent de considérer comme un problème de la communauté la question de comment les données peuvent être regroupées autour d’entités et peuvent constituer les éléments d’une définition de ce que l’on peut trouver dans un graphe nommé au niveau de l’entité. De telles initiatives existent déjà à plusieurs endroits, notamment au RCIP, à la Swiss Art Research Infrastructure (SARI) et à linked.art, entre autres. Le CRM SIG pourrait-il identifier des groupes d’entités qui devraient résider sous le même graphe nommé pour certains types d’entités?
Étant donné la diversité potentielle des champs spécifiés dans le graphe nommé, même si le même modèle est utilisé dans tout le système, les groupes créés par la stratégie de graphe nommé auront certainement un impact sur les requêtes fédérées, ce qui n’est pas encore documenté pour le moment.
Conclusion
Ce rapport a été formulé afin de résumer les résultats de l’enquête préparée pour analyser l’état actuel de l’utilisation des graphes nommés dans la communauté patrimoniale canadienne du CIDOC CRM. L’objectif était à la fois d’informer la politique interne du RCIP sur les graphes nommés et d’ouvrir une discussion plus large au sein de la communauté du CIDOC CRM et du CIDOC CRM SIG concernant la création de stratégies et de politiques générales pour l’utilisation et la mise en application des graphes nommés de manière cohérente et réutilisable (d’une manière compatible avec les objectifs généraux du CIDOC CRM et du CIDOC CRM SIG). Le présent rapport est proposé par le RCIP à titre de résumé et d’analyse initiale des résultats de l’enquête et comme moyen d’ouvrir la discussion et de susciter un débat sur les meilleures pratiques de mise en application des graphes nommés pour les données patrimoniales canadiennes à l’aide du CIDOC CRM.